
작년부터 계속 그래픽카드를 활용한 AI 기술들이 나오고 있다.
AI로 그림을 그리지 않나, AI가 대답하는 채팅봇이 나오지 않나, 심지어 이젠 AI가 목소리까지 만든다. 그야말로 온 세상이 AI 천국이다.
지금까지 나온 AI 음성 기술은 mmvc, diff-svc, ddsp-svc, so-vits-svc 등이 있었다. 이 중 mmvc를 제외하고는 모두 노래 음성을 변환하는 데 중점을 둔 기술이었다. 그리고 2023년 4월 초에 나온 것이, 바로 오늘 본문에서 다룰 RVC (Retrieval-based-Voice-Conversion-WebUI) 라는 기술이다. 기존의 기술들에 비해 그래픽카드에서 처리하는 속도가 빨라졌다는 등의 이점이 있다고 한다.
일단 목소리 모델을 만들기 위해서는, 학습할 대상의 목소리 wav 파일이 필요하다.
본인 목소리든, 다른 사람이든, 아니면 만화 캐릭터든 배경음이 없는 상태의 목소리를 녹음해야 한다.
실험을 위해 어떻게든 100개의 목소리 wav 파일을 준비하였다. 그럼 시작해보자.
* 안내
아래 설명은 2023.08.13 Nvidia (RVC-WebUI) / 1.5.3.13 (VC Client) 버전에 맞춰져 있습니다. |
1. RVC-WebUI
 |
 |
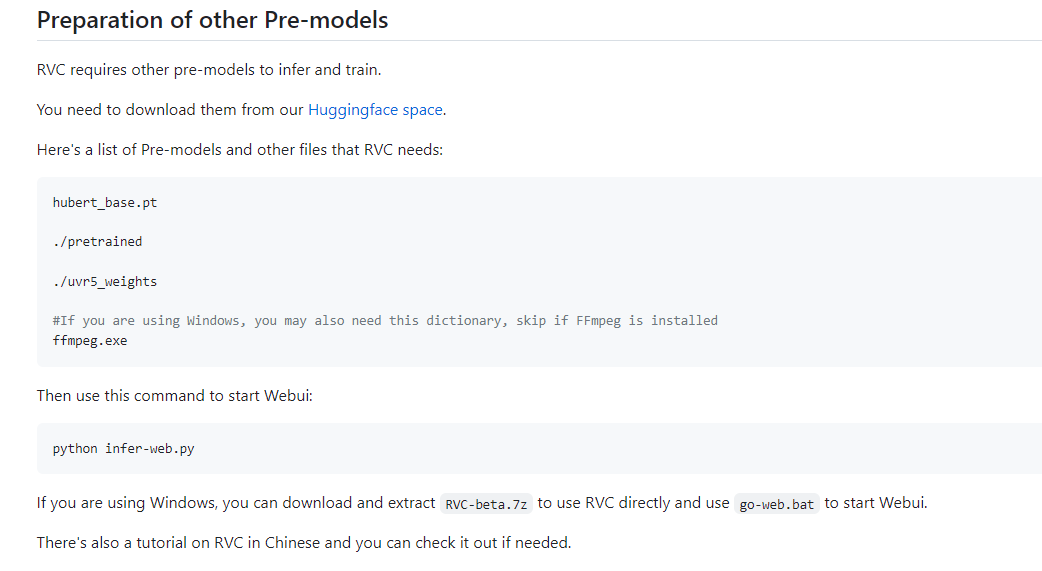
RVC 클라이언트는 Github 페이지(링크)의 Huggingface space라는 곳에서 받을 수 있었다. (링크)
거기서 RVC0813Nvidia.7z를 다운받는다. (그래픽카드가 라데온이나 인텔 내장이면 AMD_Intel 써있는 걸 받으면 된다.)
※ 매우 개인적인 생각
2023.10.06 버전은 2023.08.13 버전에서 rmvpe 추론 방식을 바꾸었다. 그런데 10.06 버전으로 목소리 변환을 해보니 어떤 목소리 모델은 08.13 버전을 사용할 때와 전혀 비슷하지 않은... 완전히 다른 사람처럼 변환이 되어버렸다. 또한 10.06 버전부터는 UI도 폴더 경로도 기존 버전과 달라져서 헷갈리기까지 한다. 그래서 나는 10.06 버전을 안 쓰기로 했다.
※ RVC 관련 설명 영상 (과거 버전 설명이지만 기록용으로 남겨둔다.)
https://www.youtube.com/watch?v=PHmePSSKD88
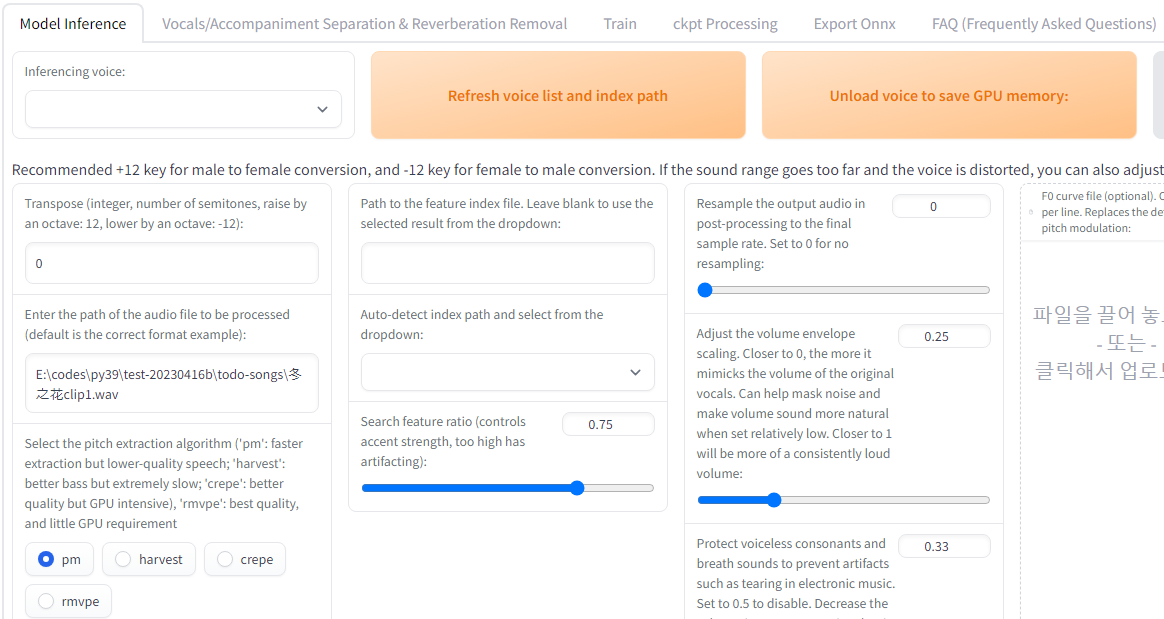
다 받은 뒤 압축 풀고 go-web.bat 파일을 누르니까 브라우저에 이런 화면이 열렸다. 목소리를 학습시키기 위해 Train 탭으로 간다.

기본값으로 두어도 되는 옵션 말고, 설명이 필요한 옵션들만 언급한다.
Enter the experiment name
: 목소리 모델의 이름을 지정한다.
Target sample rate
: 학습시킬 목소리 wav 파일의 음질을 지정한다. (44100hz면 40k, 48000hz 이상은 48k.)
pitch guidance~
: 반드시 true로 지정한다. No로 지정해버리면 목소리 모델이 보이스웨어 마냥 국어책 읽기만 하고 노래같은 건 전혀 못 부르게 된다.
Enter the path of the training folder
: 학습시킬 목소리 wav 파일이 들어가 있는 폴더를 지정한다. (학습할 wav 파일을 너무 많이 넣으면 VRAM 메모리 초과로 학습이 튕겨버리는 것 같으니 적당히 넣어야 된다. 최대 200개 정도?)
pm...CPU...dio...harvest...rmvpe...CPU/GPU
: 피치 식별 기술을 지정한다. harvest, rmvpe, rmvpe_gpu 중 하나를 선택하면 무난하다. (rmvpe 계열이 2023.09.01 기준 가장 최신 기술이다.)
Save frequency
: 학습 중간 저장 빈도를 지정한다. 하드 용량이 괜찮으면 기본값인 5로 두고, 부족하면 10으로 늘리든가 하면 된다.
Total training epochs
: 총 학습 횟수를 지정한다. 기본값인 20은 너무 적은 느낌이라서, 30으로 올린다. (30만 해도 그럭저럭 쓸만하다는 의견도 접했고, 시험삼아 100을 주고 출력시켰더니 원본 목소리와 너무 동떨어진 느낌을 받았기 때문이다.)
Batch size per GPU
: 기본값인 4로 두거나, 3으로 내린다. 이 값이 너무 높으면 VRAM 초과로 학습이 강제 중단될 수 있다. 그렇게 되면 시간만 낭비하게 된다.

아무튼 다 지정하고 아래쪽에 있는 One-click training을 누르니까 학습이 시작되었다.
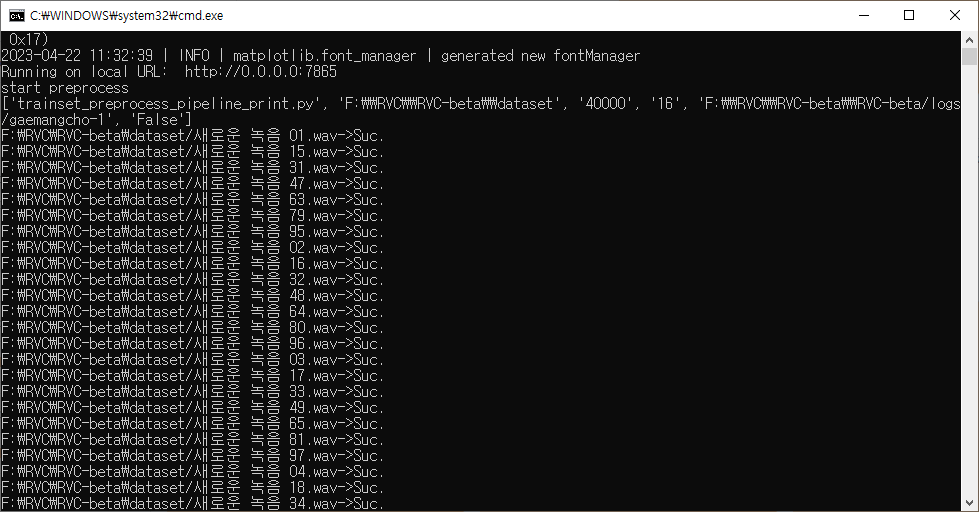
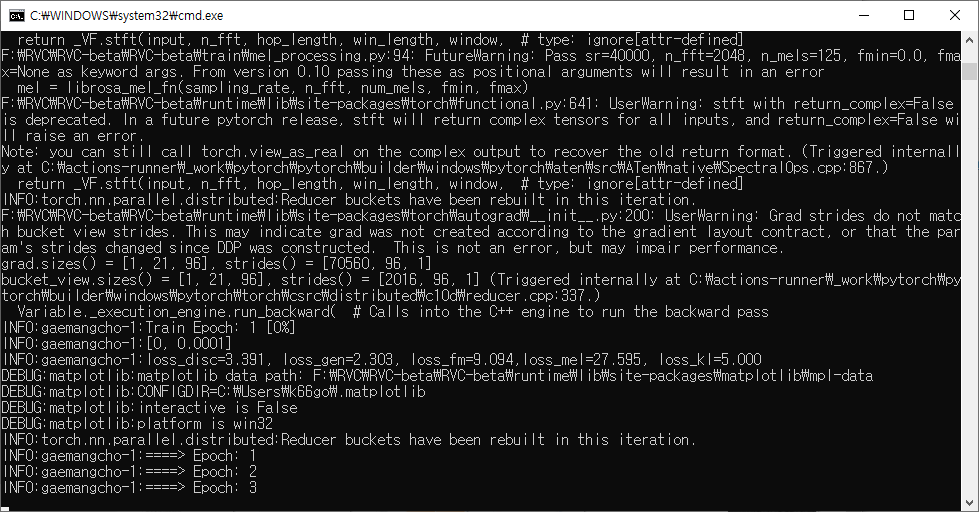
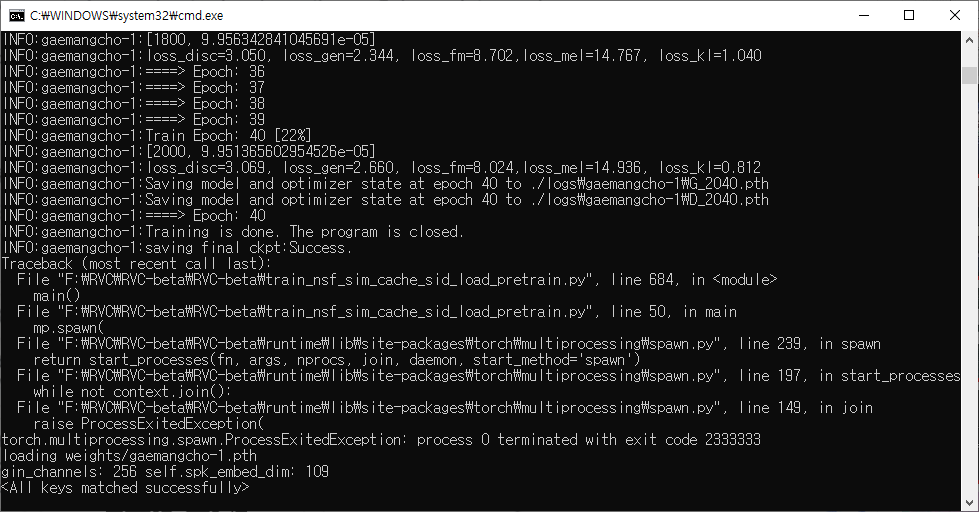
도스창에는 학습 진행 로그가 표시되었다.
설정에서 지정한 Epoch 값에 도달하니까 학습이 끝나고 weights 폴더에 목소리 모델 파일(.pth)이 생겼다.
시간은 RTX2060 Super 기준으로... 정확히 안 재봤지만 그래도 30분~1시간 정도면 다 됐던 것 같다.

다시 Model inference 탭으로 돌아가서 Refresh voice list and index path를 누른다. 그러면 Inferencing voice에 아까 만든 목소리 모델이 표시된다.
여기서도 중요한 옵션만 설명하기로 한다.
Inferencing voice
: 목소리 모델을 지정한다. (weights 폴더 내 .pth 파일을 넣으면 이 목록에 표시된다.)
Transpose
: 변환시킬 피치 값을 입력한다.
(남자 보컬 → 여자 목소리 모델 변환은 12 또는 그 이상으로 지정한다.
반대로 여자 보컬 → 남자 목소리 모델 변환은 -12 또는 그 이하로 지정한다.)
Enter the path of the audio file to be processed
: 변환시킬 보컬 wav 파일의 경로를 지정한다.
Select the pitch extraction algorithm
: 피치 식별 기술을 지정한다.
(개인적으로 rmvpe를 추천한다. 몇 개월동안 RVC 노래 테스트를 했는데... harvest는 가끔 찌그러진 부분이 나오기도 했고, crepe는 가끔 음량이 줄어들거나 쇳소리가 나는 부분도 있었다. 그러나 rmvpe는 그런 케이스가 단 한번도 없었다.)
Path to the feature index file ~
: 목소리 모델의 Index 파일 경로를 수동으로 입력하는 부분이다. 그러나 보통은 logs 폴더 밑에 목소리 모델별로 index 파일이 들어가 있을 것이다. 따라서 나는... index 파일이 없는 목소리 모델들을 변환시킬 때, 'ㅁㄴㅇㄹ' 같이 아무말이나 입력해서 변환 시 RVC가 index 파일이 없다고 간주하게 만드는 식으로 써먹고 있다.
Auto-detect index path and select from the dropdown
: logs 폴더 밑에 들어가 있는 목소리 모델 index 파일을 지정한다.
Search feature ratio
: index 파일 참조 비율을 지정한다. 높을 수록 목소리 모델 쪽의 발음/음정을 중시하며, 낮을 수록 변환시킬 보컬 wav 쪽의 발음/음정을 중시한다.
만약, 일본어로 학습된 목소리 모델에게 한국어 노래를 부르게 할 거라면 이 옵션 값을 0.1 정도로 크게 낮춰야 한다. 기본값인 0.75 정도로 두고 변환을 하면 일본인이 한국어 노래를 부르는 것처럼 어설프게 출력된다.
...이렇게 옵션 설정을 다 한 뒤에, 변환 실험을 위해 마이크와 곰녹음기를 켜고 녹음 버튼을 눌렀다.
그리고 아무말이나 한 뒤 wav 파일로 출력시켰다.
출력된 wav 파일의 경로를 넣어준 후 Conversion 버튼을 누르니...
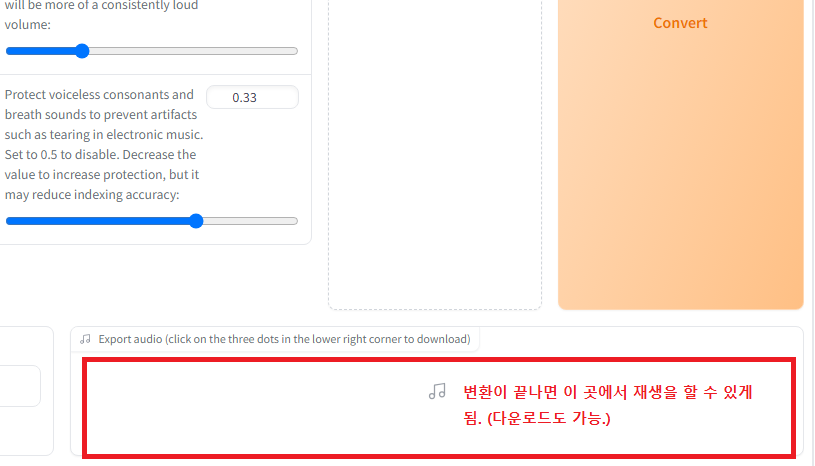
잠시 후에 변환된 음성이 Export audio ~ 부분에 나타나서 재생과 다운로드를 할 수 있었다.
그 후 위와 동일한 방식으로 VOICEVOX 즌다몬의 음성 파일도 학습시켜서 목소리 모델 파일을 출력하였다. (링크)
또한 BOOTH에서 배포 중인 목소리 모델 '유우'도 다운로드 받았다. (링크)
2. VC Client
이제 실시간으로 목소리 변환을 하기 위해 VC Client라는 RVC 호환용 보이스체인저를 사용해보도록 한다.
VC Client의 Github 페이지(링크)에 가서 클라이언트를 다운로드 받는다. 구글 드라이브 링크는 막히기 십상이니 Hugging face 쪽 링크로 다운로드 받는 것이 낫다.
윈도우 + 지포스용은 'onnxgpu_cuda' 가 파일명에 들어가 있고, 윈도우 + 라데온용은 'onnxdirectML-cuda' 가 파일명에 들어가 있으니 잘 구분해서 다운로드 받으면 된다.
다 받았으면 압축 푼 뒤에 start_http.bat를 더블 클릭한다. 그러면 실행에 필요한 파일을 추가로 다운로드 하느라 시간이 좀 더 걸린다. 대충 시간 때우고 있으면 VC Client가 알아서 실행될 것이다.
※ VC Client 관련 설명 영상 (과거 버전 설명이지만 기록용으로 남겨둔다.)
https://www.youtube.com/watch?v=z3_WqKHwtSE

실행되면 후원 좀 해달라는 메시지가 뜨는데, Start 버튼을 누르면 위와 같은 화면이 뜬다.
기본적으로 4개의 목소리 모델이 탑재가 되어있다. (츠쿠요미쨩, 아미타로, 키코토 마히로, 토키나 시구레)
그러면 클라이언트에 목소리 모델을 추가하려면 어떻게 해야 될까?
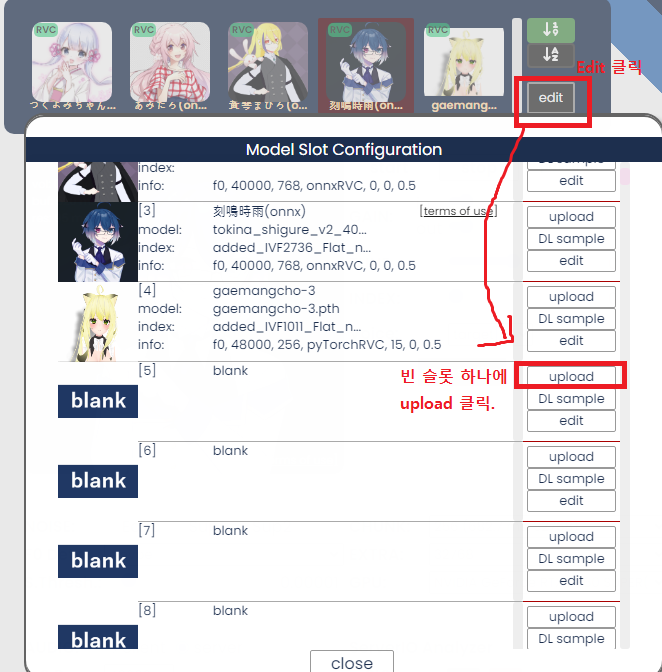 |
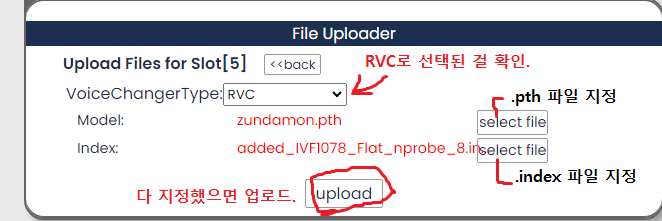 |
목소리 모델을 추가하는 방법은 다음과 같았다.
1. 목소리 모델 목록 오른쪽의 edit 버튼을 누른다.
2. 빈 슬롯에서 upload 버튼을 누른다.
3. VoiceChangerType이 RVC로 지정된 걸 확인한 뒤, Model에는 .pth 파일을, index에는 .index 파일을 지정한다. (.index 파일이 없으면 지정하지 않는다.)
4. upload 버튼 누른다.
 |
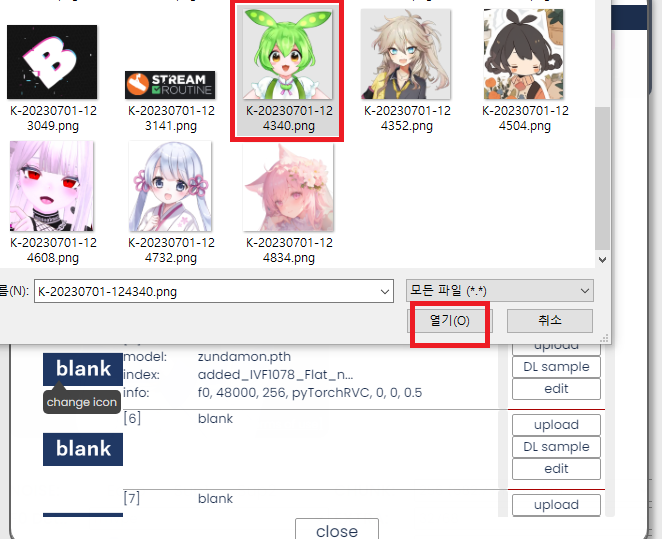 |
목소리 모델의 프로필 사진을 등록하는 방법은 다음과 같았다.
1. 등록한 목소리 모델 왼쪽의 blank를 클릭한다.
2. 프로필 사진을 연다.
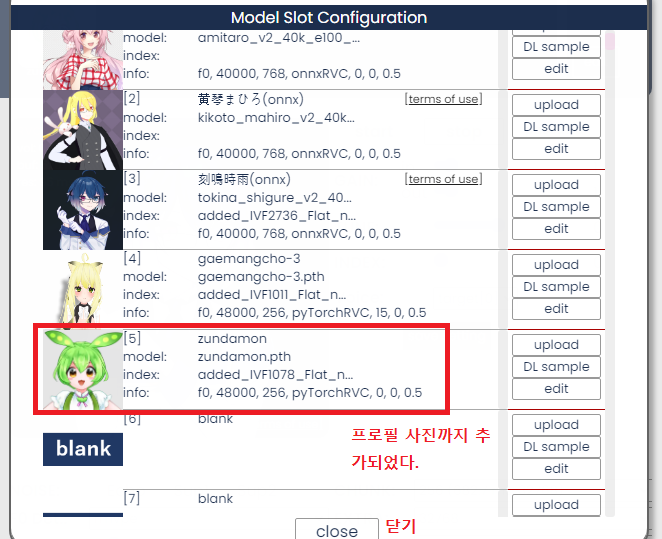
그러면 프로필 사진까지 추가된다. 이러면 목소리 모델 추가가 완료된 것이다.

등록한 목소리 모델은 목록에서 아이콘을 클릭하여 전환이 가능하다.
그러면... 설명이 필요한 옵션에 관하여 아래에다 서술하도록 하겠다. 꼭 설정이 필요한 경우는 옵션명을 빨간색으로 표시했고, 기본값으로 놔둬도 상관없으면 검은색으로 표시하였다.
GAIN - in : 본 목소리가 VC Client로 들어갈 때의 음량을 지정한다.
GAIN - out : 변환된 목소리가 출력될 때의 음량을 지정한다.
TUNE : 목소리 모델의 피치를 조절한다.
(RVC-WebUI에서 변환하는 것보다는 피치를 약간 더 높게 줘야 할 필요가 있다. 노래할 때의 음높이와 대화할 때의 음높이가 다르기 때문이다. 남자 목소리를 여자 목소리로 바꿀때는 15~18 정도로?)
INDEX : Index 파일 참조 비율을 지정한다.
(0이나 1이나 별 차이 없는 것 같다. 실시간 변환이라서 그런가? 그냥 기본값인 0으로 두는 게 낫겠다.)
save setting : 설정을 저장한다.
F0 Det.: 피치 식별 기술을 선택한다. (개인적으로는 rmvpe를 추천함)
CHUNK : 목소리 변환의 지연 시간을 지정한다. 지연 시간을 길게 잡을 수록 변환 품질이 증가한다고 한다.
(이건 실험해보니... 8~24로 지정하면 도스창에 오류만 뜨면서 변환이 안 되고, 32는 약간 문제가 있게 변환되며, 40 이후부터 정상적으로 변환이 이루어졌다.)
EXTRA : CPU가 변환에 얼마나 도움을 주는지를 지정한다.
(32768 까지는 CPU 자원을 많이 안 쓰는데, 65536 이상부터는 CPU 점유율이 급격히 상승하는 걸 확인할 수 있었다.)
GPU : 목소리 변환을 GPU가 주도할지, 아니면 CPU가 주도할지를 지정한다. (그냥 GPU가 주도하는 게 낫다.)
AUDIO : 오디오 구성 방식을 지정한다. 클라이언트와 서버 방식이 있는데, 서버 방식을 추천한다. (응답 시간이 좀 더 빠르다고 들은 것 같다.)
(서버 방식으로 설정했을 경우)
S.R.: 목소리 모델의 Hz를 선택한다. 대부분은 48000Hz일 것이니, 48000으로 선택한다.
input : 마이크 장치를 지정한다. 그냥 [MME]로 들어간 걸 선택하면 된다.
output : 변환된 목소리가 출력될 단자를 지정한다. VoiceMeeter나 VB-Cable 같은 걸 깔았으면 대충 그런 단어가 붙어있는 단자로 지정하면 된다. 이것도 그냥 [MME]로 들어간 걸 선택하면 된다.
(클라이언트 방식은 S.R. 옵션만 없을 뿐 나머지는 똑같다.)
설정이 다 됐으면 맨 위의 start 버튼을 누른다. 누르고 말을 하면 약간의 딜레이 후에 목소리가 변환되어 출력될 것이다.
변환을 중지하려면 stop을 누르면 되고, passthru는 변환없이 본 목소리 그대로 출력되는 기능이니 조심할 것.
만약 OBS를 통해 노래 녹음을 하고 싶다면, buf(ms) + 680 (res x3인가? 왜 그런지는 불명. 내 컴퓨터에선 이 값이 맞았다.) 의 값만큼 데스크탑 오디오 싱크를 뒤로 미루면 된다. 노래방 MR화면도 '효과 - 렌더링 지연' 기능으로 화면 출력을 뒤로 미루면 된다. 맞춰야 할 싱크 ms는 각자의 컴퓨터 설정에 따라 달라질 수 있으므로, 위의 계산식으로도 맞지 않으면 알아서 조정하기 바란다.
(다만, 노래는 VC Client를 통해 부르는 것보다 그냥 본 목소리로 녹음한 뒤 RVC-WebUI에서 변환 처리를 거치는 게 낫다. VC Client를 통해 부르면 늘어뜨리는 파트[이 발음, 우 발음] 에서 잘못된 발음이 출력되는 문제가 있다. 어느 정도 업데이트가 이루어진 2023.09.01에도 마찬가지다.)
마지막으로 RVC를 통해 만들어진 목소리 모델을 가지고, VC Client로 목소리를 바꾼 뒤 일반적인 대화와 노래 테스트를 한 영상을 첨부한다.
* 일반적인 대화
(2023.04.24 설명 영상에서 2024.01.30 설명 영상으로 교체.)
* 노래 테스트
아래의 테스트 영상은 모두 본 목소리로 녹음 후 변환 처리(Model inference - Conversion) 하였다. (나는 이 방식을 사후변환 방식이라고 부르고 있다. VC Client로 부른 건 실시간 방식이라 부르고...)
(위의 설명 영상에서 실시간 방식으로 불렀던 노래를 사후변환 방식으로 다시 부른 것.)
(현재 유튜브 채널 메인에 등록되어 있는 곡.)
사실 버미육 도전은 이미 끝났기 때문에, 이러한 기술을 알아낸다 하더라도 굳이 목소리 모델을 만들고, 노래를 부르고, 영상을 올리고, 블로그에 글을 쓸 이유는 없다. 그냥 남들이 해놓은 거 구경만 하면 된다.
하지만 굳이 이렇게까지 한 이유는 뭘까?
어쩌면 이런 식으로라도 버추얼 개망초를 살리고 싶어서 그랬는지도 모르겠다.
아무튼 불과 반 년전만 해도 나한테는 전혀 관련이 없을 것 같았던 별의 별 기술들을 다 경험해본다.
그럼 이만...
※ 위의 곡을 포함하여 다른 노래 테스트 곡을 들으려면 이 게시물을 참조.
'버미육' 카테고리의 다른 글
| 프리블록스 VRM 용량 제한 해제는 아프리카TV에서 활동해야만 해준다고 한다. (0) | 2023.09.12 |
|---|---|
| RVC 보이스체인저 노래 테스트 정리. (0) | 2023.04.28 |
| 버미육 도전일기... - 30부 (完) (4) | 2023.04.14 |
| 버미육 도전일기... - 29부 (0) | 2023.04.05 |
| 버미육 도전일기... - 28부 (0) | 2023.03.29 |
